Integrating Till with Kimurai
Integration Steps:
Integrating Till with Kimurai
Integration Steps:
Till can be easily integrated with your Kimurai scraper without much code changes.
Please follow the steps below.
Follow the instructions to install Till
Next, you need to modify your existing Kimurai Scraper to integrate with Till.
The following is an example script:
# Code example from https://github.com/gitter-badger/kimurai
require 'kimurai'
class GithubSpider < Kimurai::Base
@name = "github_spider"
@engine = :mechanize
@start_urls = ["https://github.com/search?q=Ruby%20Web%20Scraping"]
@config = {
# Integrate with Till
proxy: "localhost:2933:http",
ignore_ssl_errors: true,
# IMPORTANT: Custom headers in Kimurai only works on :mechanize and :poltergeist_phantomjs drivers
# (Selenium don't allow to set/get headers)
headers: {
# Add the header to force a Cache Miss on Till
"X-DH-Cache-Freshness" => "now",
},
}
def parse(response, url:, data: {})
response.xpath("//ul[@class='repo-list']/div//h3/a").each do |a|
request_to :parse_repo_page, url: absolute_url(a[:href], base: url)
end
if next_page = response.at_xpath("//a[@class='next_page']")
request_to :parse, url: absolute_url(next_page[:href], base: url)
end
end
def parse_repo_page(response, url:, data: {})
item = {}
item[:owner] = response.xpath("//h1//a[@rel='author']").text
item[:repo_name] = response.xpath("//h1/strong[@itemprop='name']/a").text
item[:repo_url] = url
item[:description] = response.xpath("//span[@itemprop='about']").text.squish
item[:tags] = response.xpath("//div[@id='topics-list-container']/div/a").map { |a| a.text.squish }
item[:watch_count] = response.xpath("//ul[@class='pagehead-actions']/li[contains(., 'Watch')]/a[2]").text.squish
item[:star_count] = response.xpath("//ul[@class='pagehead-actions']/li[contains(., 'Star')]/a[2]").text.squish
item[:fork_count] = response.xpath("//ul[@class='pagehead-actions']/li[contains(., 'Fork')]/a[2]").text.squish
item[:last_commit] = response.xpath("//span[@itemprop='dateModified']/*").text
save_to "results.json", item, format: :pretty_json
end
end
GithubSpider.crawl!
Note: To see a working example, you can visit this link.
Next, run your Kimurai Scraper like you normally would.
Note: If you don't have an existing Kimurai Scraper to try with Till, you can try our working example here.
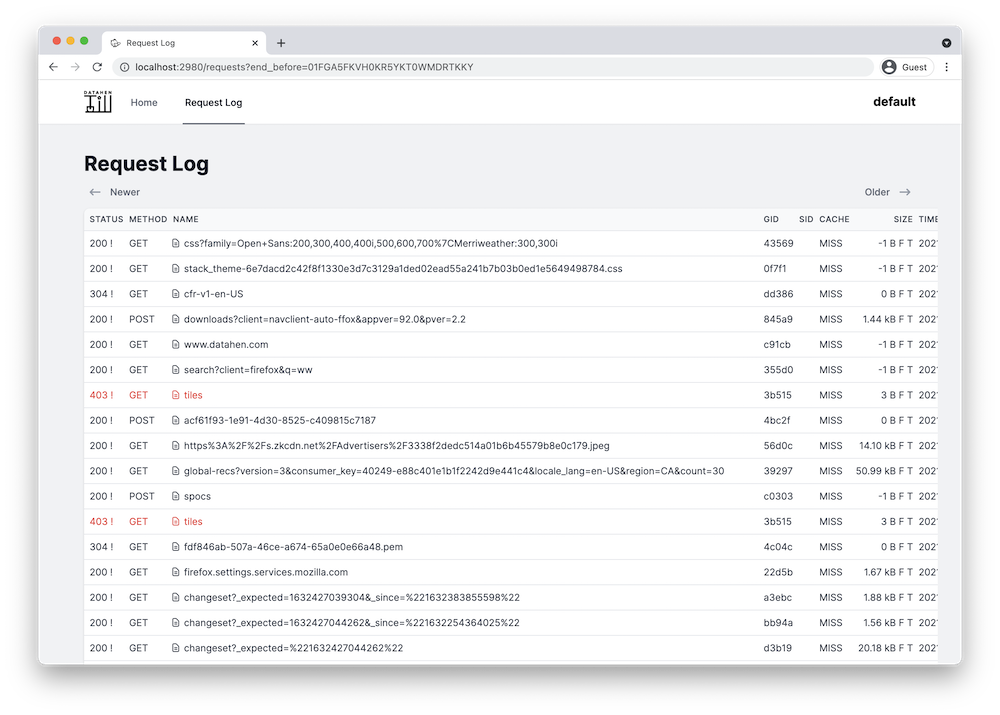
Visit the Till UI at http://localhost:2980/requests to see that your new requests are shown.
Getting Started
How To Use
Integrations
Python
Node.js
Go
Ruby